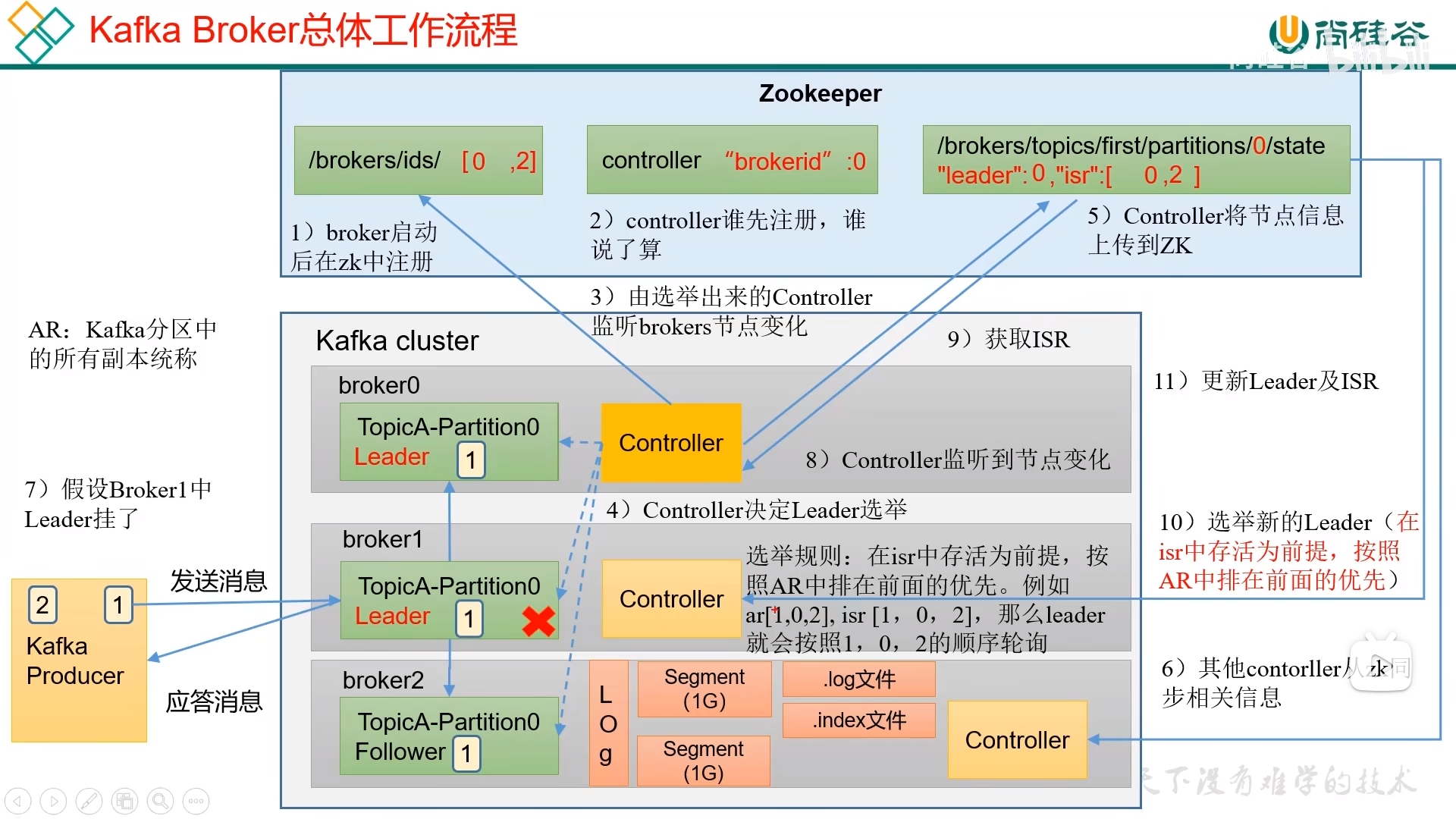
Kafka Broker
工作流程
副本
基本信息
(1)Kafka 副本作用:提高数据可靠性。
(2)Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会 增加磁盘存储空间,增加网络上数据传输,降低效率。
(3)Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader, 然后 Follower 找 Leader 进行同步数据。
(4)Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms 参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本。
Leader 选举流程
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader,负责管理集群 broker 的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。
Controller 的信息同步工作是依赖于 Zookeeper 的。
故障处理细节
LEO (Log End Offset):每个副本的最后一个 offset,LEO 其实就算最新的 offset + 1
HW (Hign Watermark):所有副本中最小的 LE O
Follower
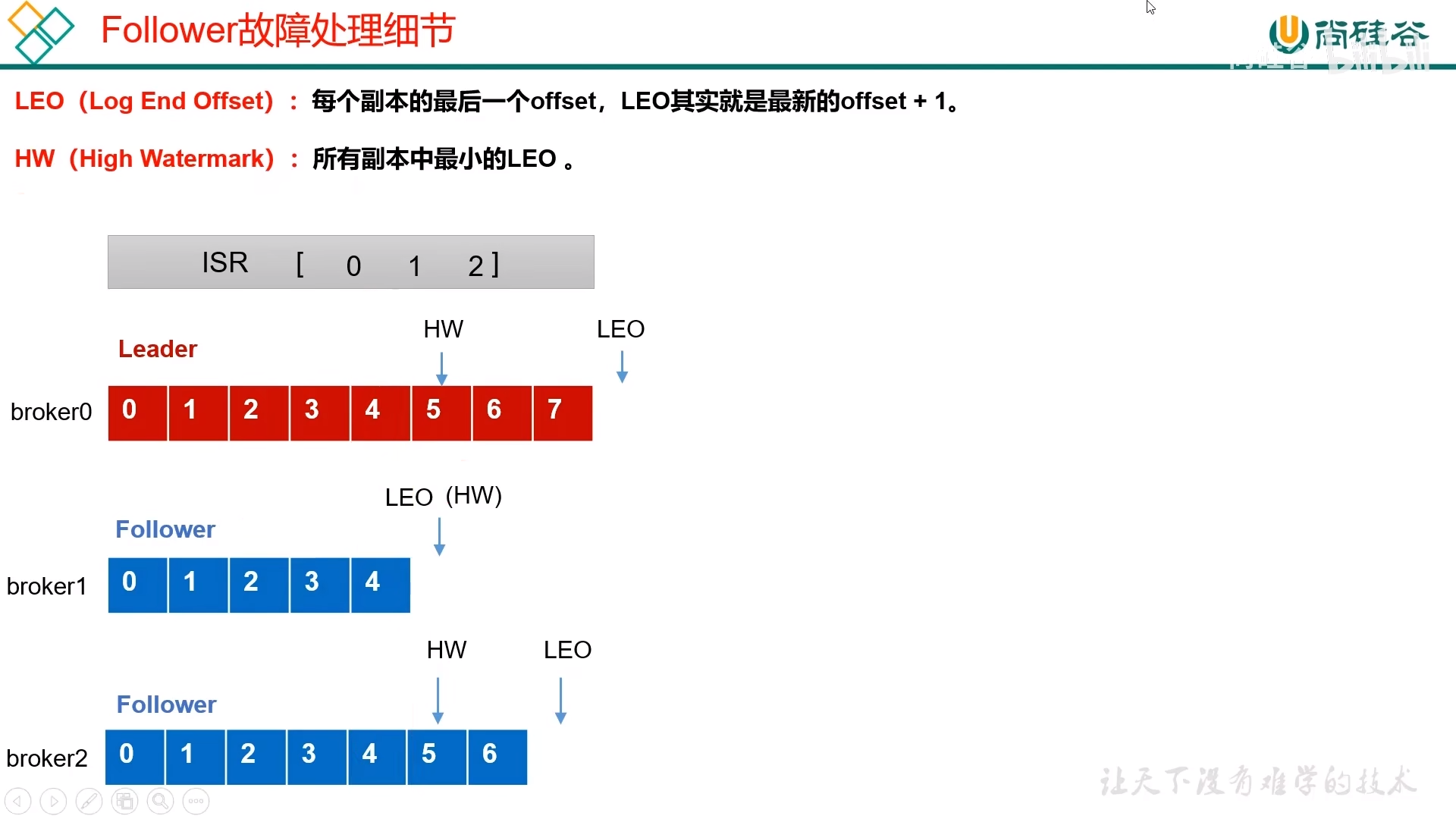

Leader

文件存储机制
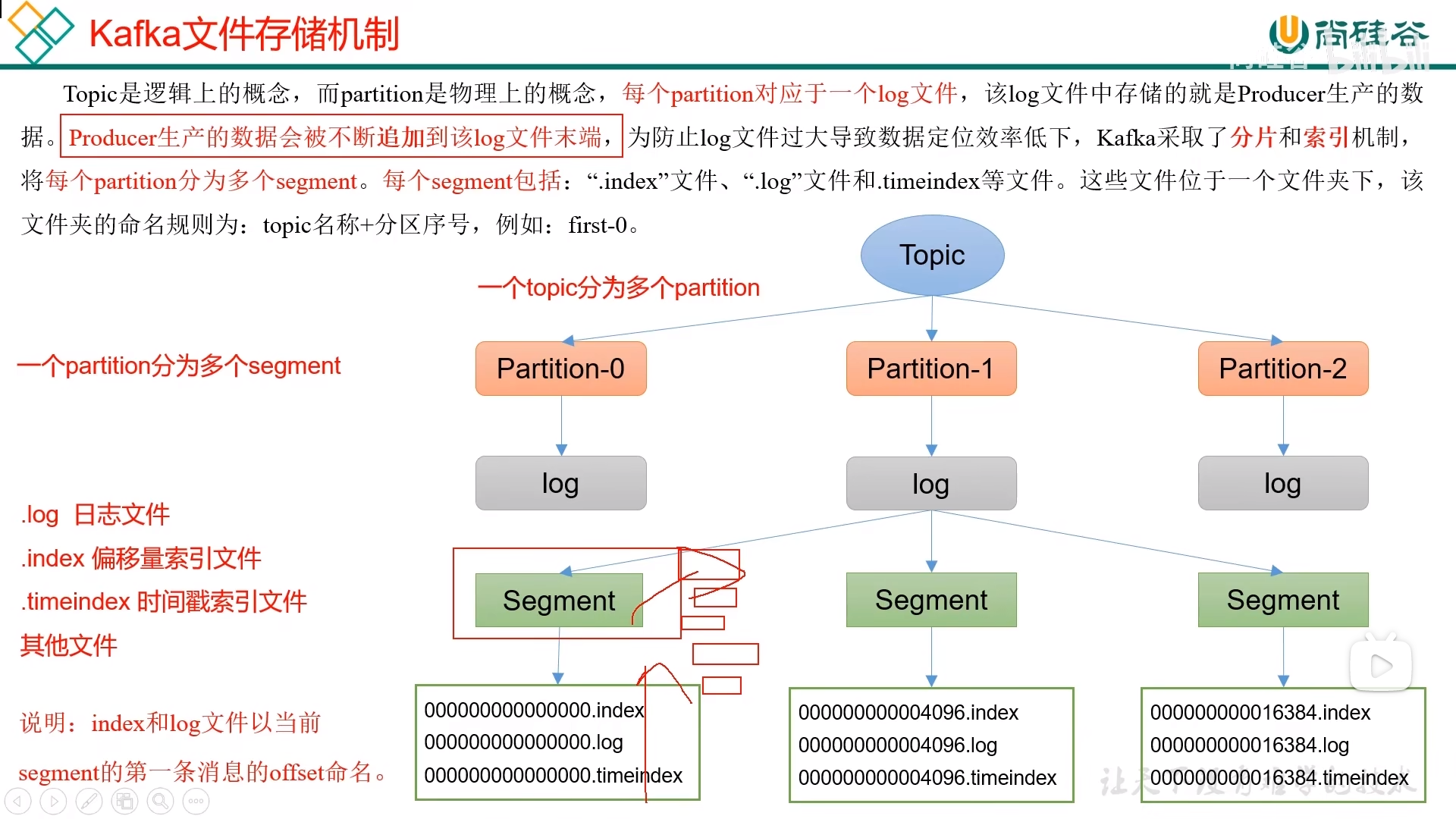
注意:
- .index 为稀疏索引,大约每往 log 文件写入 4kb 数据时,会往 index 文件写入一条索引。参数
log.index.interval.bytes默认是 4kb - index 文件中保存的 offset 为 相对 offset,这样能确保 offset 的值所占空间不会过大,因此能将 offset 的值控制在固定大小
高校读写数据
原因:
Kafka 本身是分布式集群,可以采用分区技术,并行度高
读数据采用稀疏索引,可以快速定位要消费的数据
顺序写磁盘
官网有数据表明,顺序写能到 600M/s 而随机只有 100K/s 之所以快,是其省去了大量磁头寻址的时间零拷贝:Kafka 的数据加工处理操作交由 Kafka 生产者 和 Kafka 消费者处理。 Kafka Broker 应用层不关心存储的数据,所以就不用走应用层,传输效率高
页缓存:Kafka 重度依赖底层操作系统提供的 PageCache 功能。当上层有写操作时,操作系统只是将数据写入 PageCache 中。当读操作发生时,先从 PageCache 中查找,找不到再去磁盘读取。实际上 PageCache 是把尽可能多的空闲内存当作了磁盘缓存来使用
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!