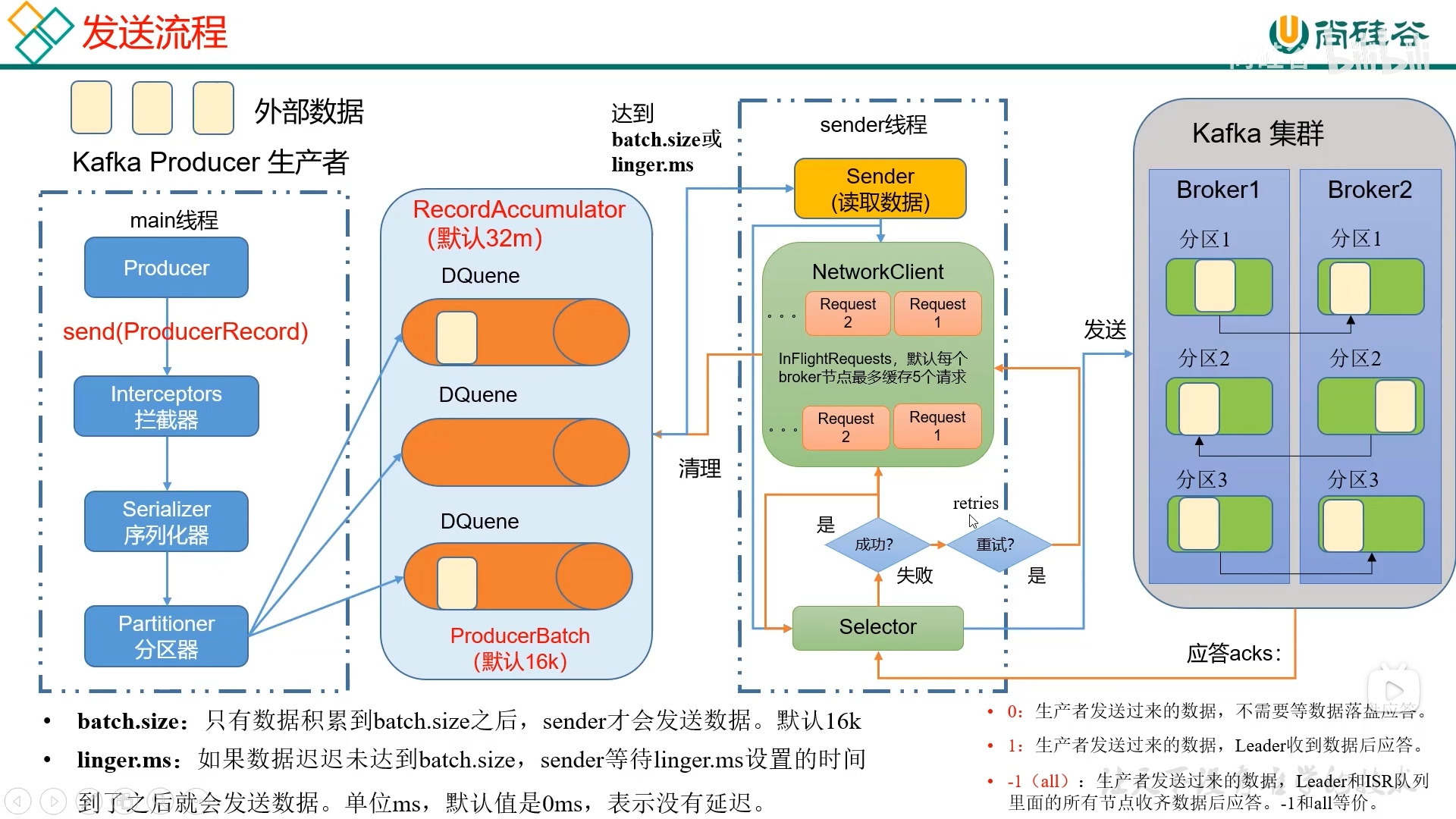
一、消息发送
1. 发送原理
在消息发送的过程中,涉及两个线程
创建双端队列 RecordAccumulator(默认大小 32 M),并将消息发送到 RecordAccumulator
不断地从 RecordAccumulator 中拉取消息发送到 Kafka Broker
ISR = 与 leader 保持正常通讯的节点
也就是为和 Leader 保持同步数据的所有副本集合
2. 异步发送 API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class Producer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:port");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "rovingsea" + i));
}
kafkaProducer.close();
}
}
|
3. 同步发送 API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class Producer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:port");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "rovingsea" + i)).get();
}
kafkaProducer.close();
}
}
|
4. 回调发送 API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public class ProducerCallback {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:port");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "rovingsea" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
System.out.println("主题:" + recordMetadata.topic() + "->" + "分区" + recordMetadata.partition());;
} else {
e.printStackTrace();
}
}
});
TimeUnit.SECONDS.sleep(1);
}
kafkaProducer.close();
}
}
|
二、分区
1. 好处
- 合理使用存储资源,从而达到负载均衡地效果
- 提高并行度,生产者可以分区发送数据;消费者可以分区消费数据
2. 策略

3. 自定义策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class DivPartition implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String msgValues = value.toString();
int partition;
if (msgValues.equals("rovingsea")) {
partition = 0;
} else {
partition = -1;
}
return partition;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> map) {}
}
|
三、提高吞吐量
合理调整四个参数:
- batch.size,默认16k
- linger.ms,默认 0s,也就是没有延迟
- compression.type,压缩方式
- RecordAccumlator,缓冲区大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class KafkaParameter {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
}
}
|
四、数据可靠
主要依据应答级别 acks
- 0,生产者发送过去的数据,不需要然后应答,也就是发送消息后就不管了
Leader 已经挂了,不确定是否消费了
如果Leader收到后,还没来得及同步,就挂了,那么也会导致数据丢失
- 1,生产者发送过去的数据,需要
Leader收到数据后并应答
- 如果
Leader收到数据后应答了,但还没来得及同步,就挂了,而此时生产者也不会向新Leader再次发送相同的消息,所以会导致数据丢失
- all(-1),生产者发送过去的数据,需要
Leader + ISR(In-Sync Replicas) 应答

但是如果在 Leader与数据同步结束后,正准备发送应答 ACK时就挂了,那么生产者会认为 Kafka集群没有消费,所以会重新发送一次,这样就会导致数据重复
五、幂等性和生产者事务
1. 幂等性
在确保数据可靠性的条件下,可能会出现数据重复的现象

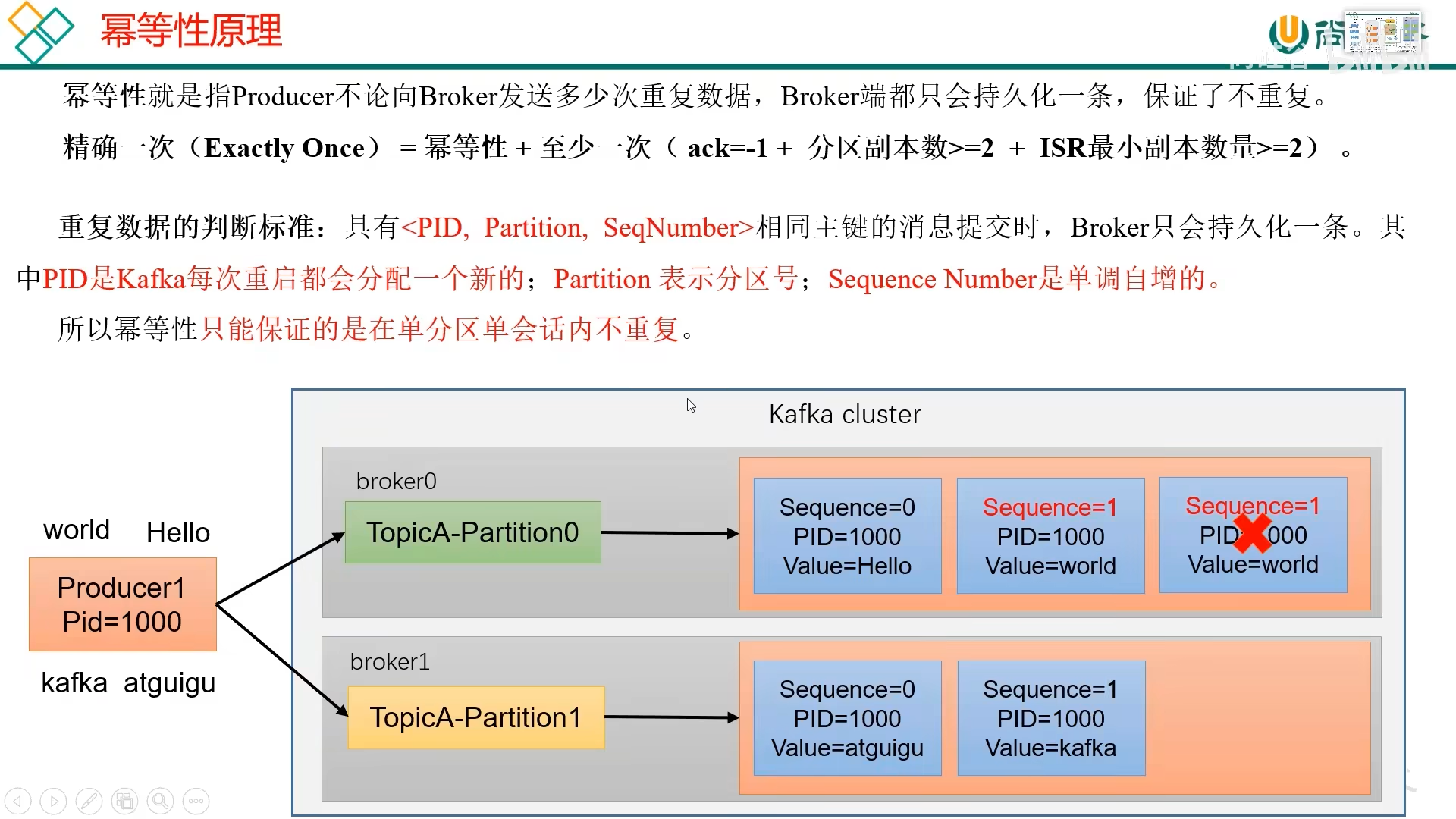
开启幂等性,默认是开启的
1
| enable.idempotence = true
|
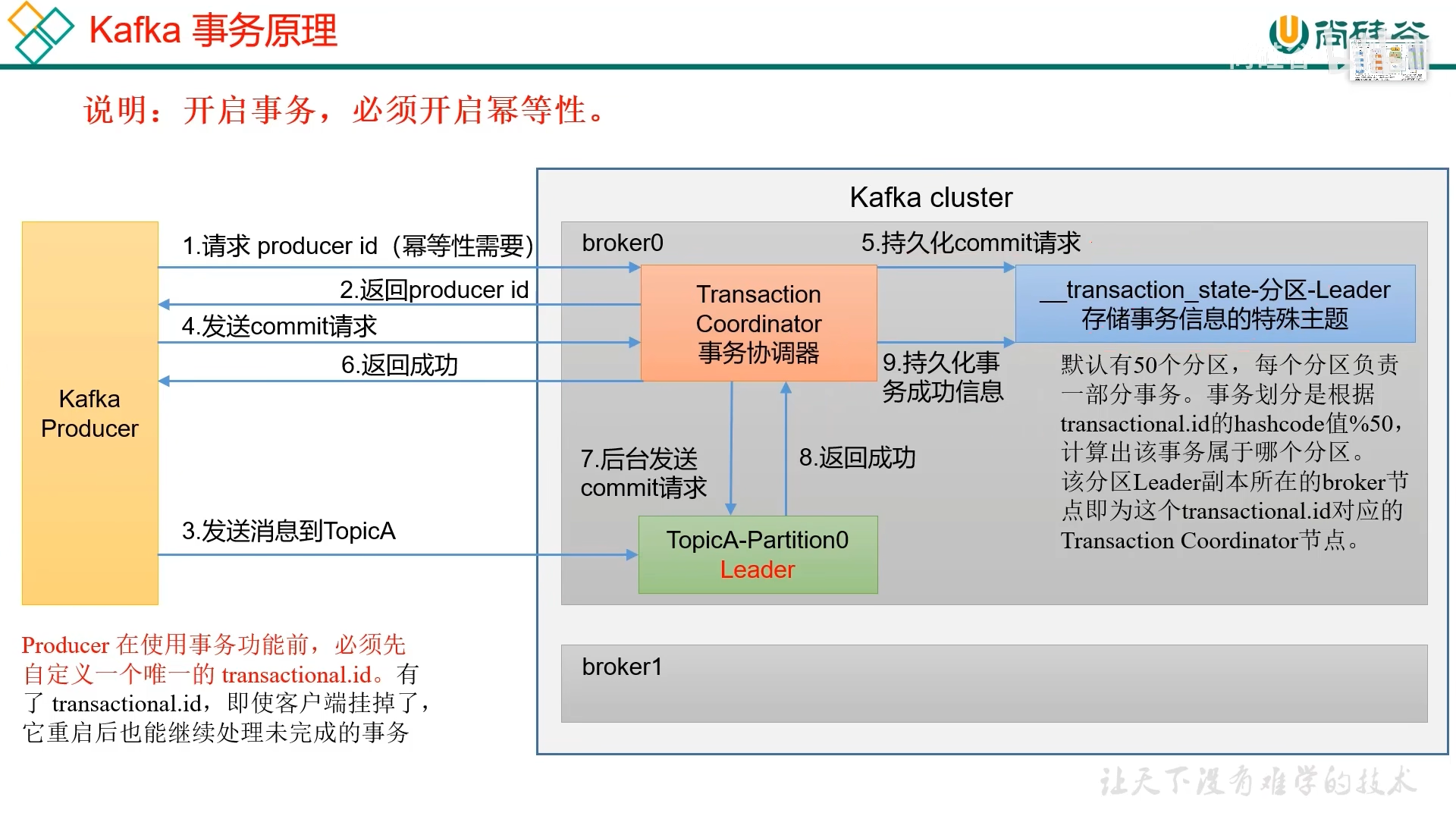
2. 生产者事务
幂等性只能保证在单分区单会话内不重复
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public class ProducerTransaction {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:port");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "rovingsea");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
kafkaProducer.initTransactions();
kafkaProducer.beginTransaction();
try {
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "rovingsea" + i));
kafkaProducer.commitTransaction();
}
} catch (Exception e) {
kafkaProducer.abortTransaction();
} finally {
kafkaProducer.close();
}
}
}
|
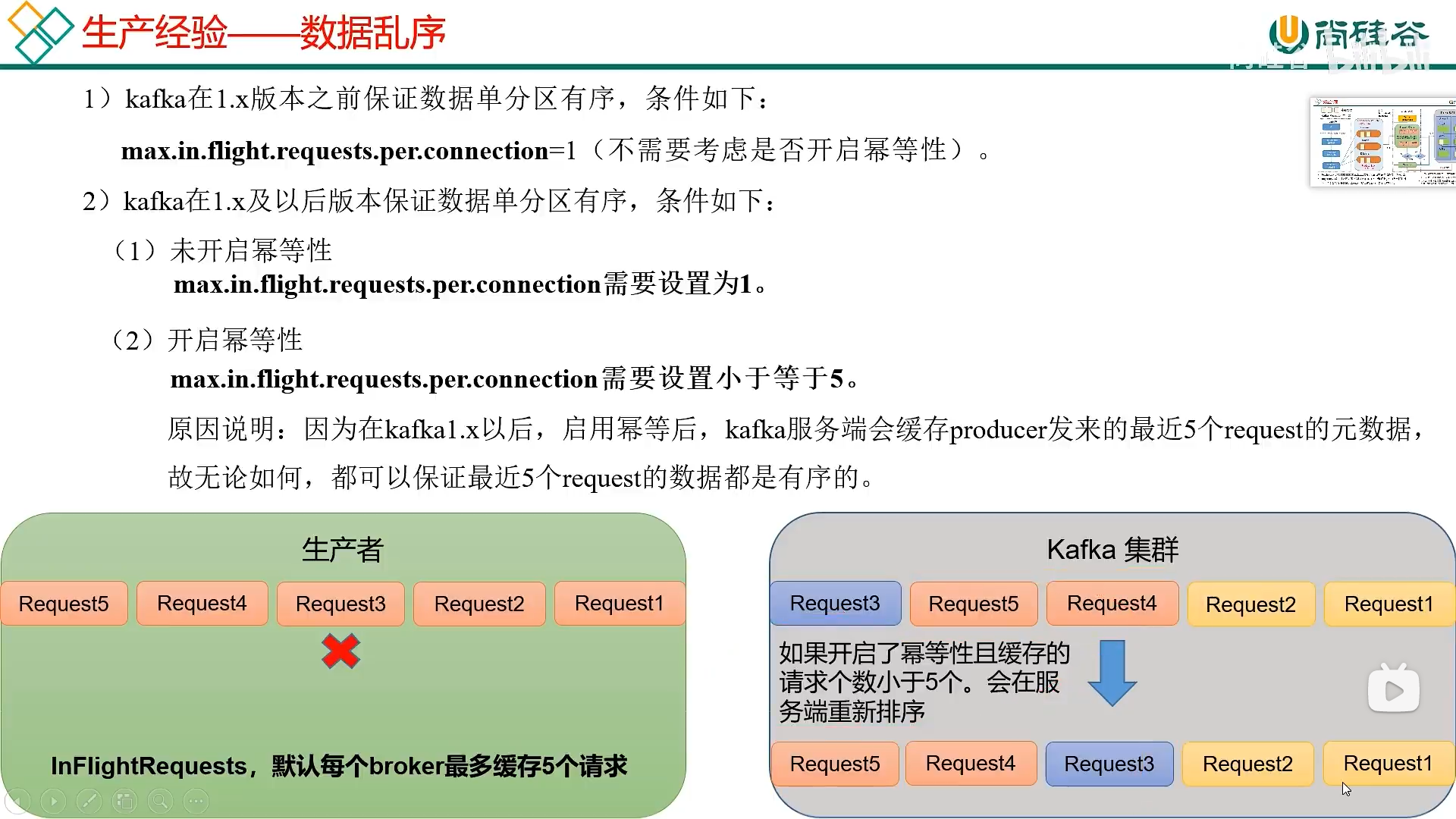
六、数据有序
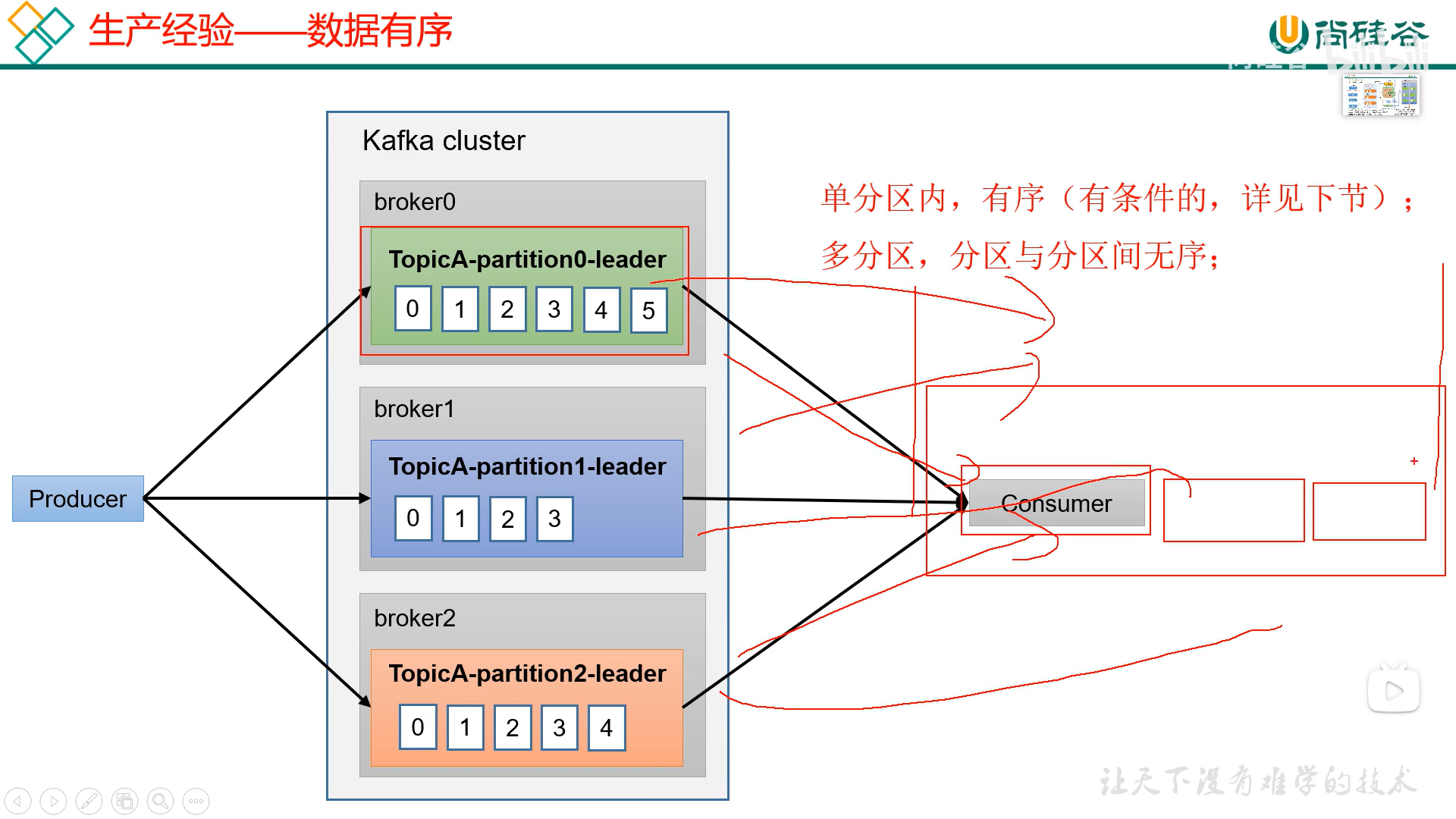
实现原理: