运行时架构
系统架构
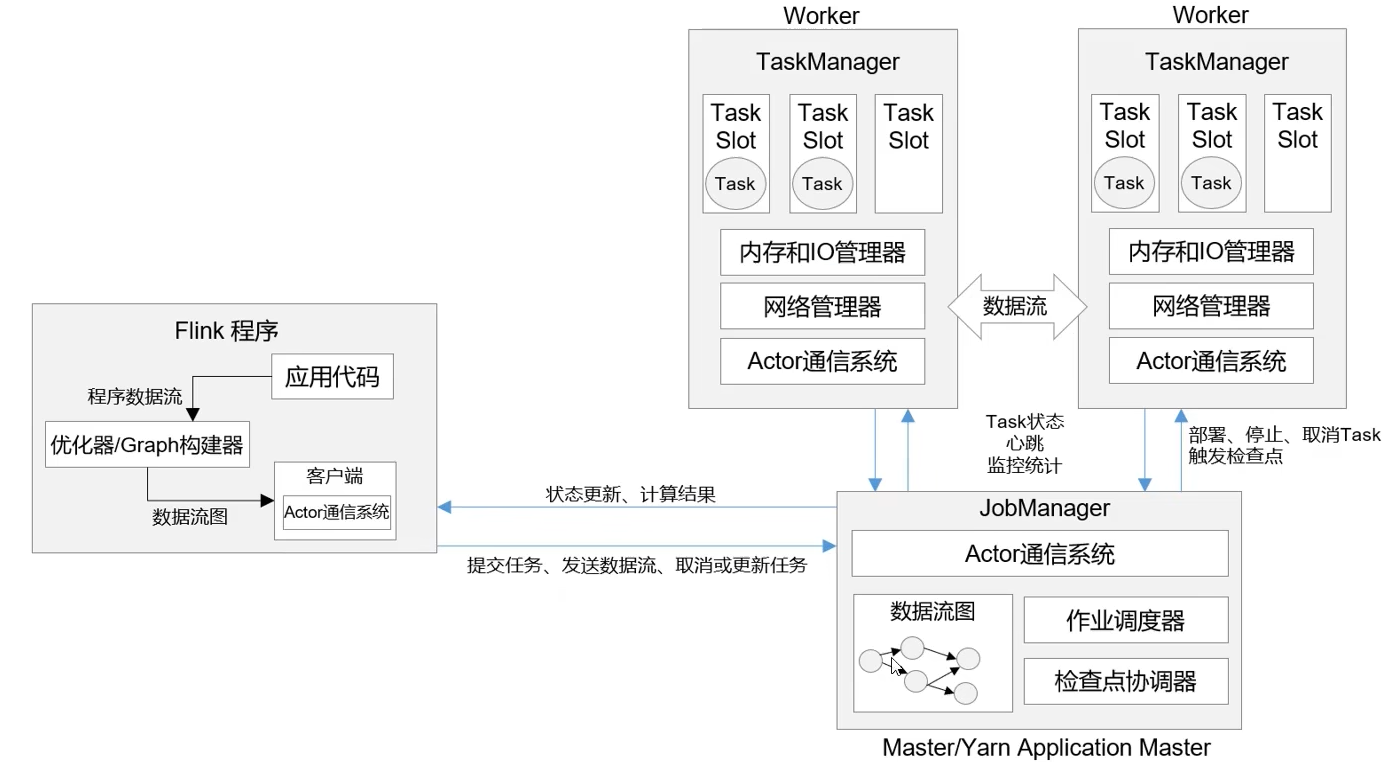
运行时组件
作业管理器

任务管理器
资源管理器

分发器

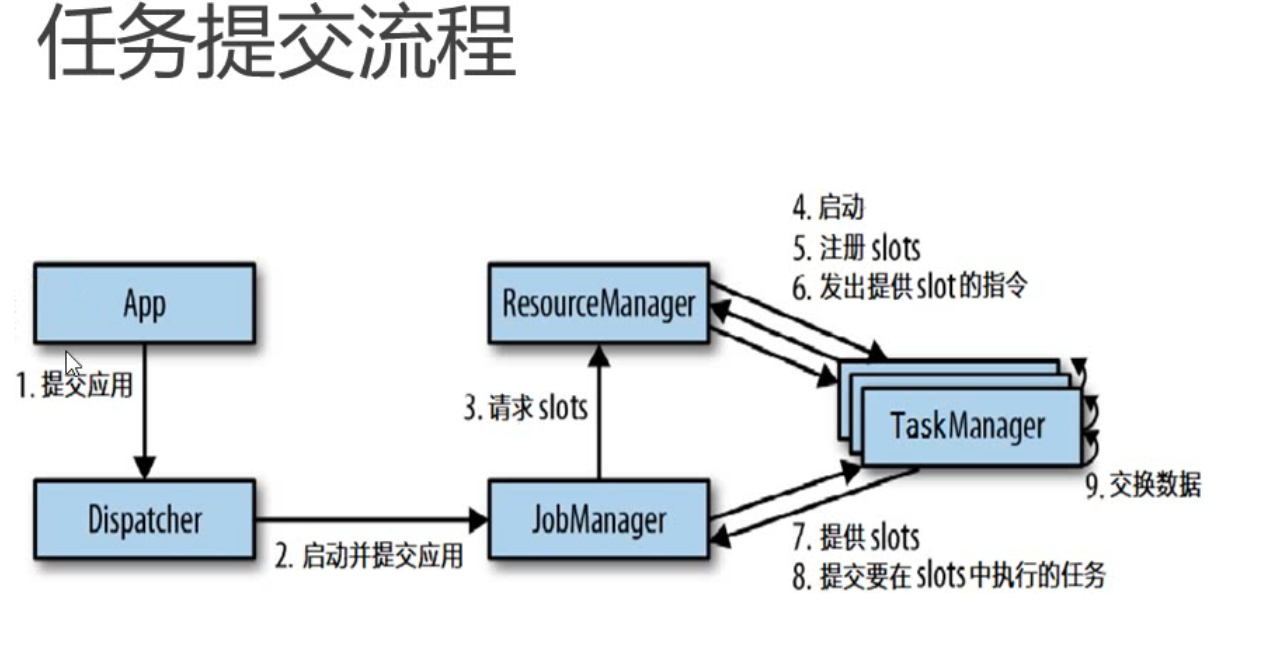
任务提交流程
抽象概念
单机模式
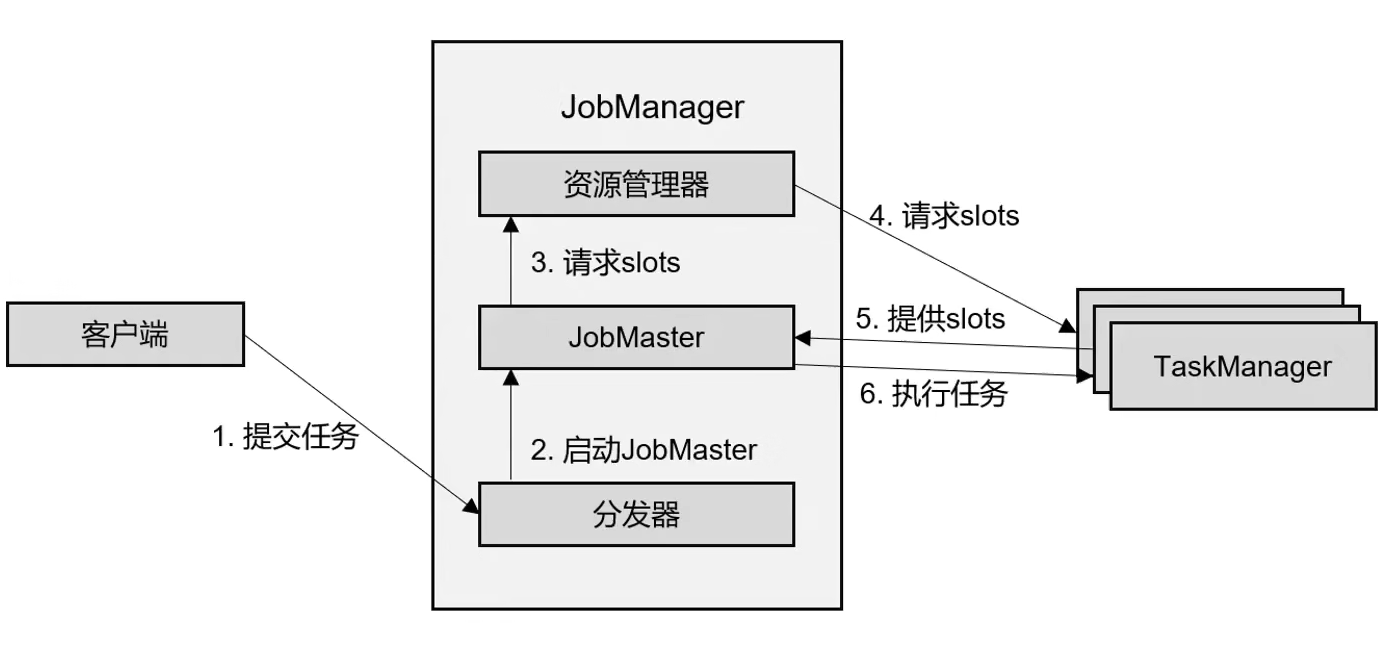
Yarn 环境
会话模式
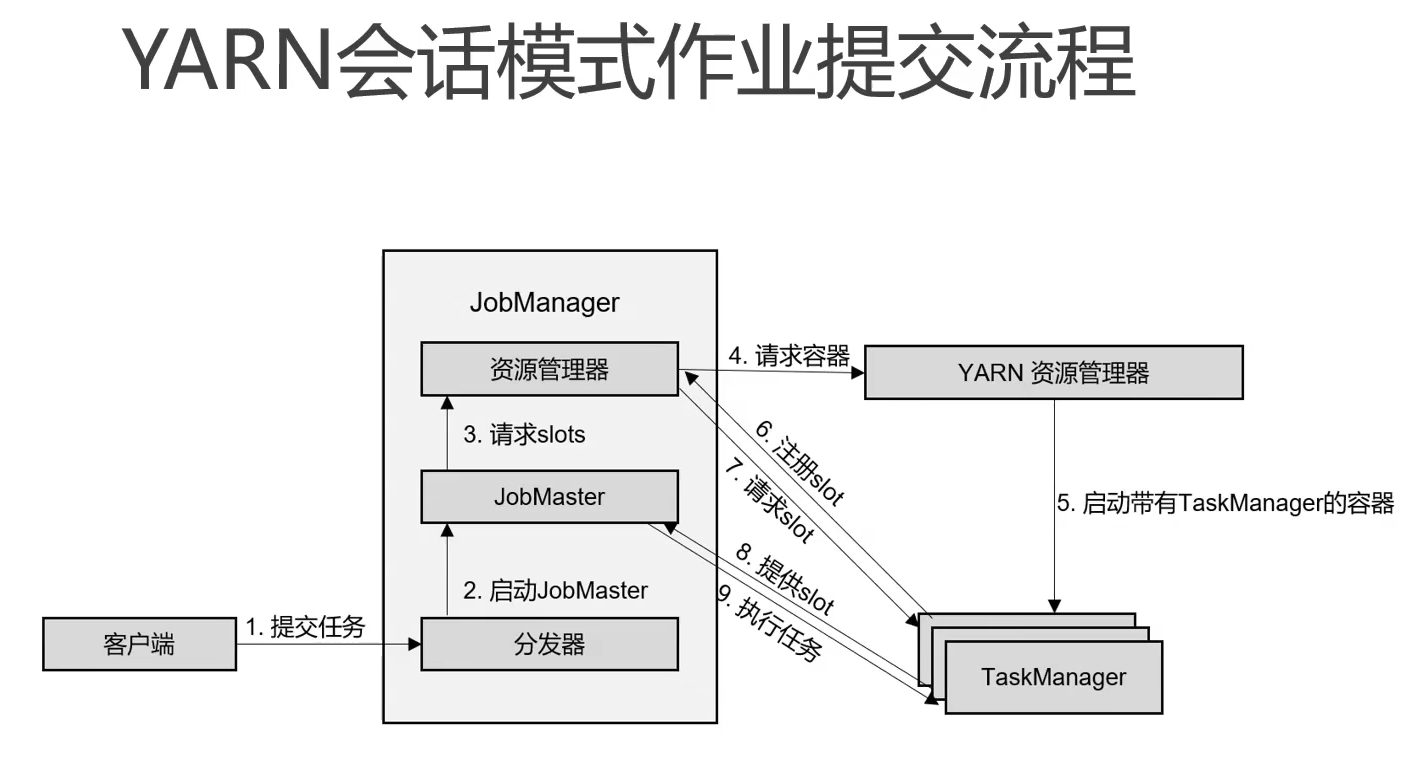
单作业模式
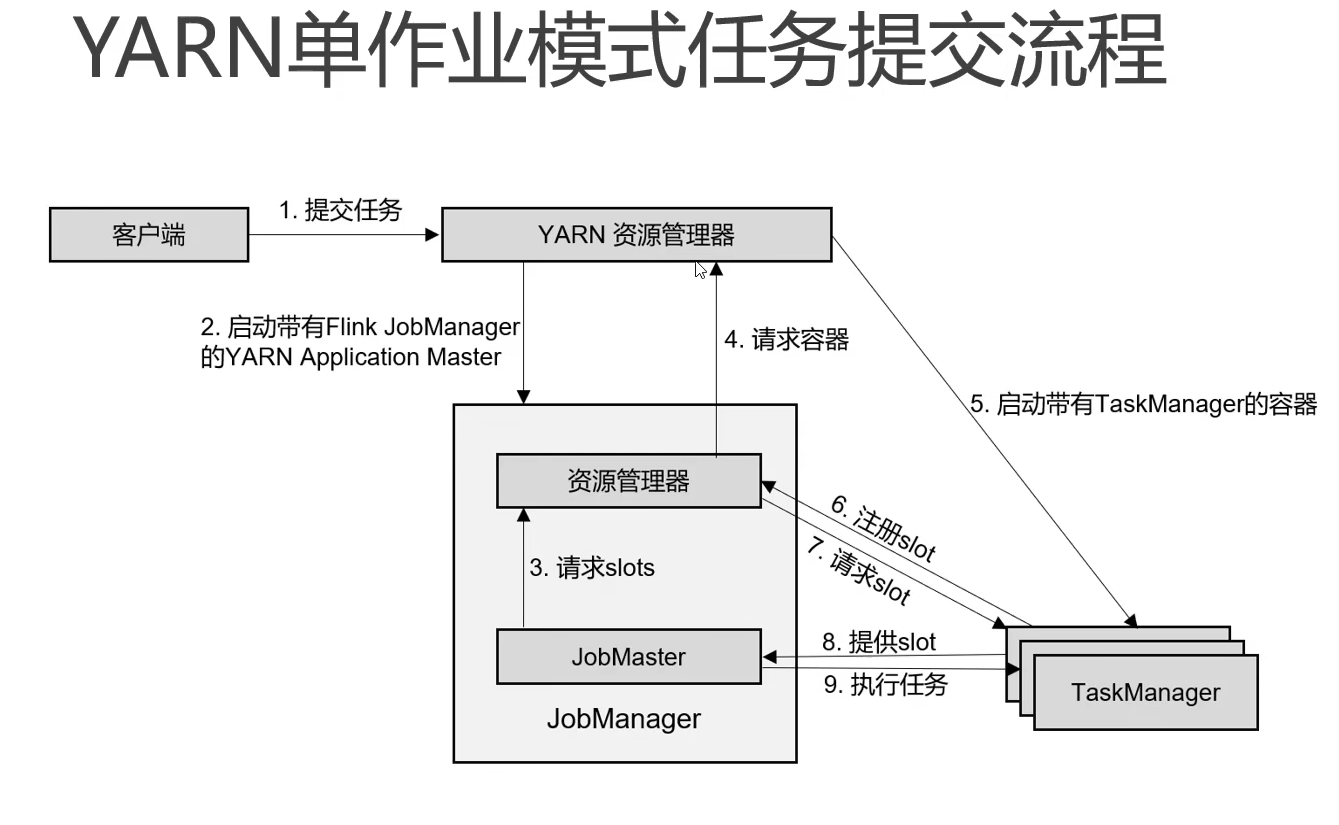
重要概念
程序与数据流
Flink 是流式计算框架。它的程序结构,其实就是定义了一连串的处理操作,每一个数据 输入之后都会依次调用每一步计算。在 Flink 代码中,我们定义的每一个处理转换操作都叫作 “算子”(Operator),所以我们的程序可以看作是一串算子构成的管道,数据则像水流一样有序 地流过。
所有的 Flink 程序都可以归纳为由三部分构成:Source、Transformation 和 Sink。
- Source 表示“源算子”,负责读取数据源
- Transformation 表示“转换算子”,利用各种算子进行处理加工
- Sink 表示“下沉算子”,负责数据的输出
在运行时,Flink 程序会被映射成所有算子按照逻辑顺序连接在一起的一张图,这被称为 “逻辑数据流”(logical dataflow),或者叫“数据流图”(dataflow graph)。
并行度
概念
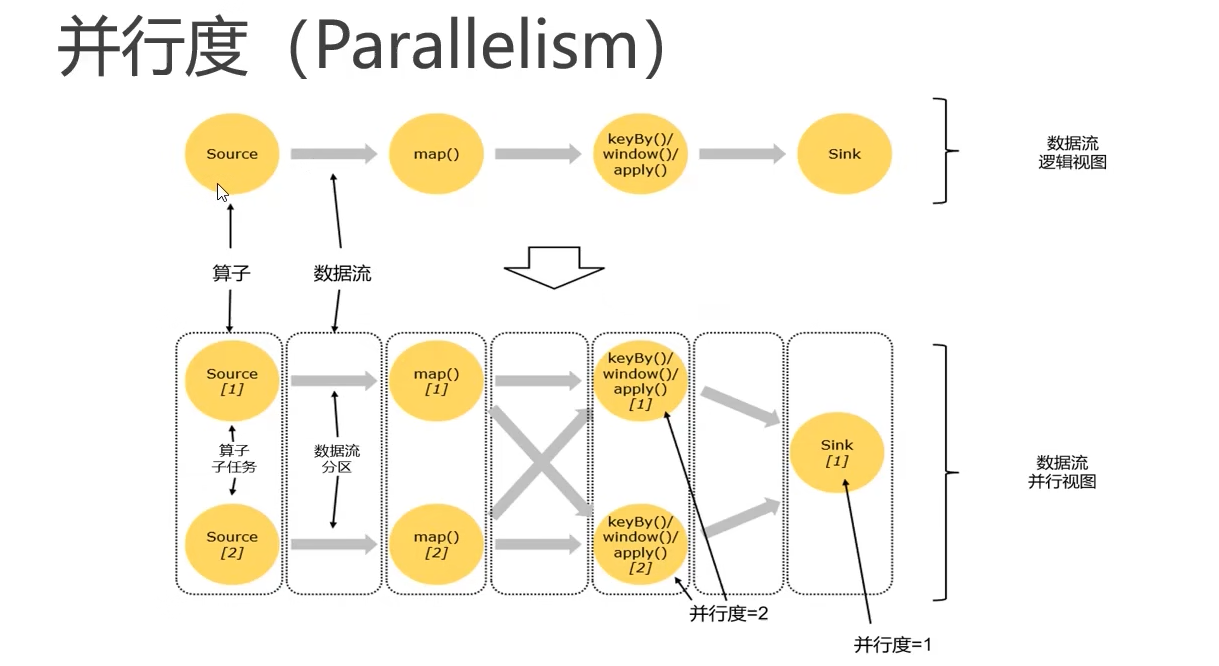
- 一个特定“算子”的子任务
(subtask)的个数被称之为其并行度(parallelism) - 一般情况下,一个
stream的并行度,可以认为就是其所有算子中最大的并行度
如上图所示,当前数据流中有 source、map、window、sink 四个算子,除最后 sink,其他算子的并行度都为 2。整个程序包含了 7 个子任务,至少需要 2 个分区来并行执行。我们可以说,这段流处理程序的并行度就是 2。
设置
在 Flink 中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
代码
我们在代码中,可以很简单地在算子后跟着调用 setParallelism()方法,来设置当前算子的并行度:
1 | |
这种方式设置的并行度,只针对当前算子有效
提交
在使用 flink run 命令提交应用时,可以增加 -p 参数来指定当前应用程序执行的并行度, 它的作用类似于执行环境的全局设置:
1 | |
配置文件
我们还可以直接在集群的配置文件 flink-conf.yaml 中直接更改默认并行度:
1 | |
这个设置对于整个集群上提交的所有作业有效,初始值为 1。无论在代码中设置、还是提 交时的-p 参数,都不是必须的;所以在没有指定并行度的时候,就会采用配置文件中的集群 默认并行度。在开发环境中,没有配置文件,默认并行度就是当前机器的 CPU 核心数
优先级
- 对于一个算子,首先看在代码中是否单独指定了它的并行度,这个特定的设置优先级 最高,会覆盖后面所有的设置
- 如果没有单独设置,那么采用当前代码中执行环境全局设置的并行度
- 如果代码中完全没有设置,那么采用提交时-p 参数指定的并行度
- 如果提交时也未指定-p 参数,那么采用集群配置文件中的默认并行度
算子链
如上图所示,一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通 (forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
一对一
这种模式下,数据流维护着分区以及元素的顺序。
比如图中的 source 和 map 算子,source 算子读取数据之后,可以直接发送给 map 算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。
这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着“一对一”的关系。
map、filter、flatMap 等算子都是这种 one-to-one 的对应关系。
这种关系类似于 Spark 中的窄依赖。
重分区
在这种模式下,数据流的分区会发生改变。
比图中的 map 和后面的 keyBy/window 算子之 间(这里的 keyBy 是数据传输算子,后面的 window、apply 方法共同构成了 window 算子), 以及 keyBy/window 算子和 Sink 算子之间,都是这样的关系。
每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。
比如从并行度为 2 的 window 算子,要传递到并行度为 1 的 Sink 算子,这时的数据传输方式是再平衡(rebalance),会把数据均匀地向下游子任务分发出去。
这些传输方式都会引起重分区(redistribute)的过程,这一过程类似于 Spark 中的 shuffle。
总体说来,这种算子间的关系类似于 Spark 中的宽依赖。
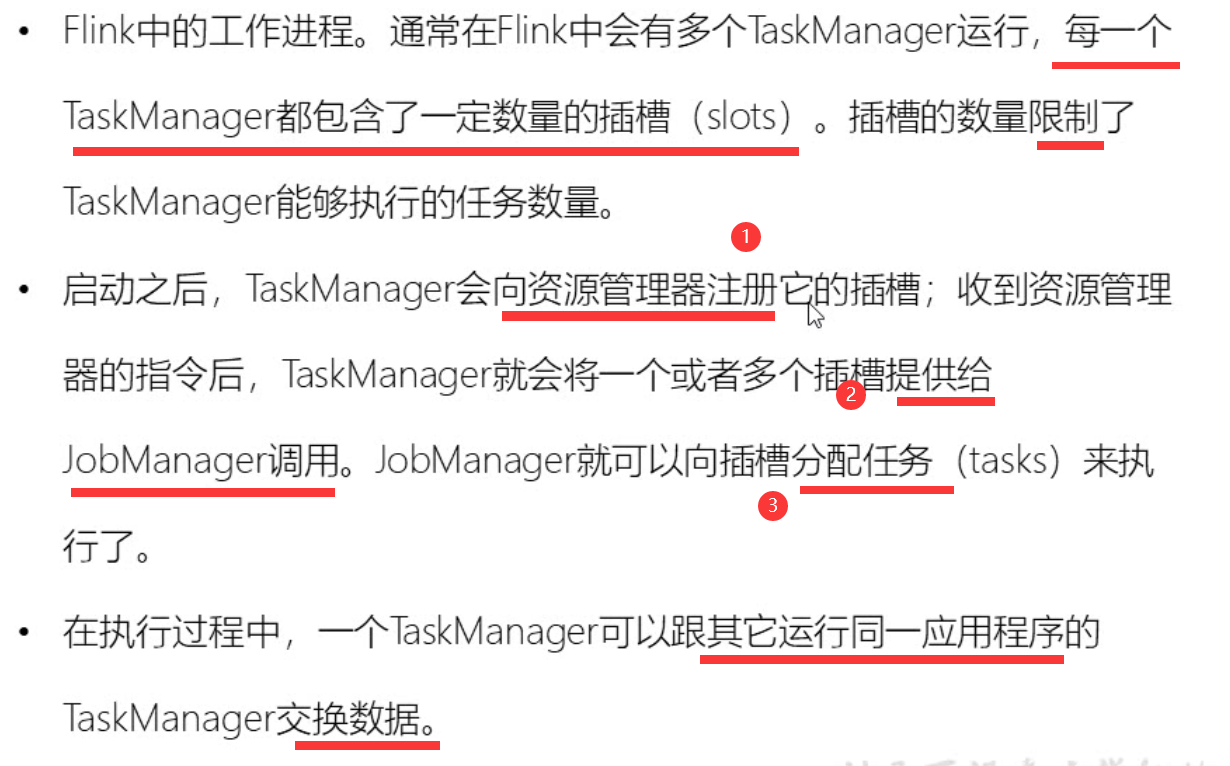
TaskManager 和 Slots
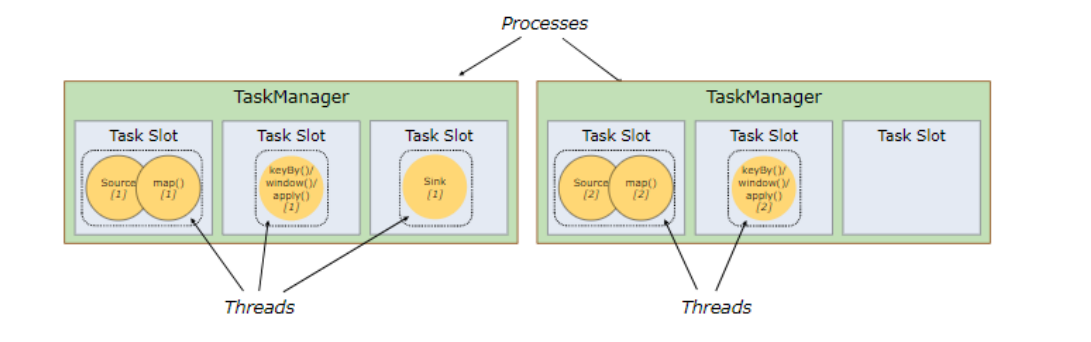
Flink中每一个TaskManager都是一个JVM进程,它可能会在独立的线程上执行一个或多个子任务- 为了控制一个
TaskManager能接收多少个task,TaskManager通过task slot来进行控制(一个TaskManager至少有一个slot)
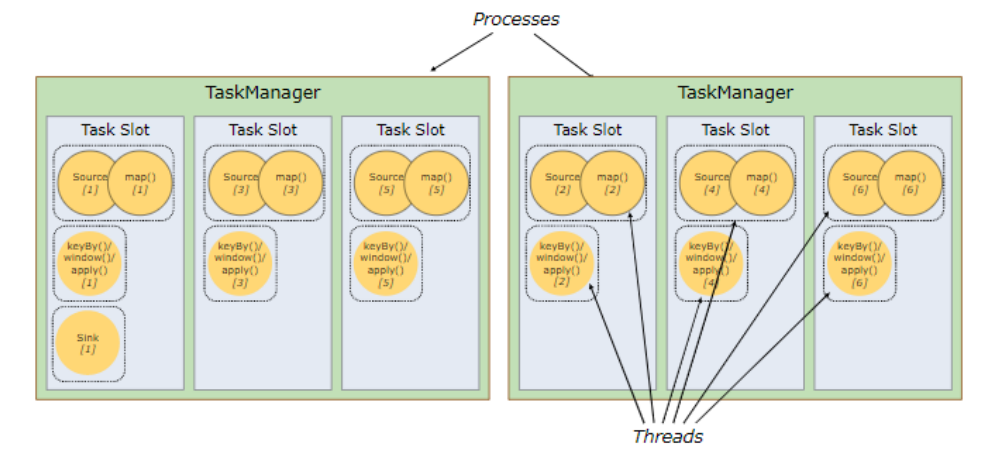
- 默认情况下,
Flink允许子任务共享slot,即使它们是不同任务的子任务。 这样的结果是,一个slot可以保存作业的整个管道。 Task Slot是静态的概念,是指TaskManager具有的并发执行能力
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!