九大数据结构
String
| 一个key对应一个value
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
字符串value最多可以是512M
|
数据结构
1
2
3
| 简单动态字符串(Simple Dynamic String,缩写SDS),类似于Java的ArrayList
当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
|

List
1
2
3
| 列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)
底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
|
数据结构
1
2
3
4
5
6
7
| 压缩链表zipList和快速链表quickList
链表元素较少的情况时使用一块连续的内存存储,这个结构是zipList,它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
数据量比较多的时候才会改成quickList,因为普通的链表需要的附加指针空间太大,会比较浪费空间。
将链表和ziplist结合起来组成了quicklist,也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
|

Set
1
2
3
| 与list类似是一个列表的功能,特殊之处在于set是可以自动排重的
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
|
数据结构
1
2
3
4
5
| Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。
Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
|
Hash
1
2
3
| 是一个键值对集合
一个string类型的field和value的映射表,hash特别适合用于存储对象。类似Java里面的Map<String,Object>
|
数据结构
1
2
3
| 压缩链表zipList和哈希表hashTable
当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
|
Zset
1
2
3
4
5
6
7
| 有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
|
数据结构
1
2
3
4
5
| Hash和跳跃表skipList
hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
|
跳跃表
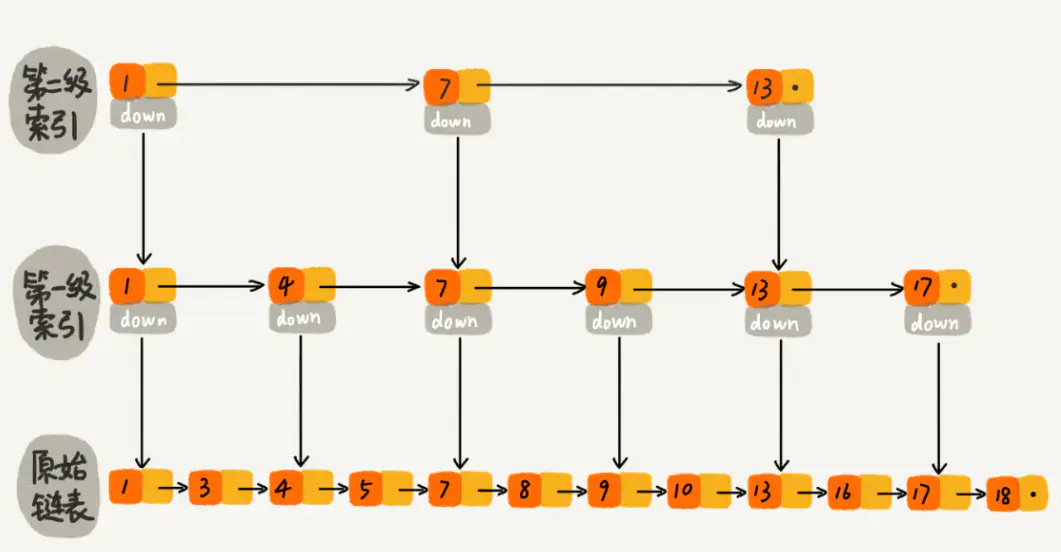
1
| 从高层索引寻找,如果发现小于则跳跃,如果发现大于则向低一层索引查找,直到查找到为止。
|
BitMaps
HyperLogLog
Geospatial
Streams