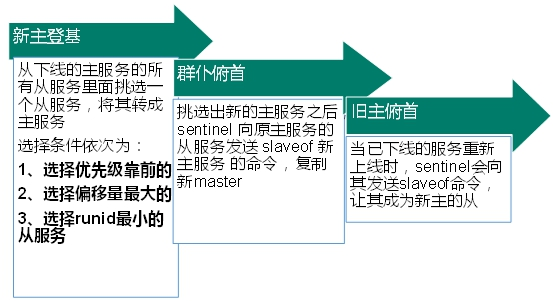
主从复制原理
全量复制
| 1. 主节点通过bgsave命令fork子进程进行RDB持久化,该过程非常消耗CPU、内存(页表复制)、磁盘I/O
2. 主节点通过网络将RDB文件发送给从节点,对主节点的带框会带来很大的消耗
3. 从节点清空老数据、载入新RDB文件,其过程是阻塞的,无法响应客户端命令;如果从节点执行bgrewriteaof,也会带来额外的消耗
|
增量复制
1
2
3
4
5
6
7
8
| 1. 复制偏移量:执行复制的主从节点,分别会维护一个偏移量offset,用来记录下一次同步从哪儿开始
2. 复制积压缓冲区:主节点内部维护了一个固定长度的、先进先出的队列作为复制积压缓冲区,当主从节点offset的差距过大超过缓冲区时,将无法执行部分复制,只能执行全量复制
使用缓冲区可以避免从节点要去主节点的硬盘中获取数据
3. 每个Redis节点,都有其运行ID,运行ID由节点在启动时自动生成,主节点会将自己的运行ID发送给从节点,从节点会将主节点的运行ID保存起来。从节点Redis断开重连的时候,就会根据运行ID来判断同步的进度:
3.1. 如果从节点保存的运行ID与主节点的运行ID相同,说明主从节点之前同步过,主节点会继续尝试使用增量复制(到底能不能复制还得 看offset和复制积压缓冲区的情况)
3.2. 如果从节点保存的运行ID与主节点的运行ID不相同,说明从节点在断开前同步的Redis节点并不是当前的主节点,只能进行全量复制
|
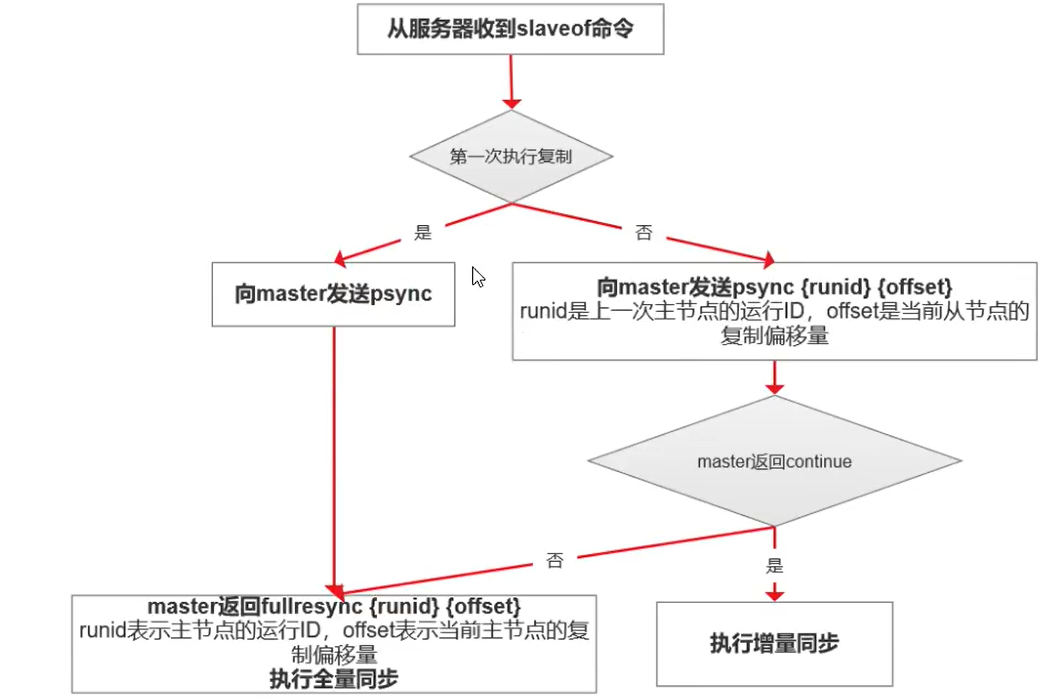
故障恢复